
The Queen's Gambit
NVIDIA just made its most consequential bet on open AI (not OpenAI). What does it mean for who gets to build the future and who gets left on the subscription tier? Come along, we'll find out!!

Jensen Huang does not do small moves, does he?

At GTC 2026, while the rest of the room was still processing the chonky hardware announcements, he dropped something that I think is going to look much bigger in 12-18 months than it does right now.
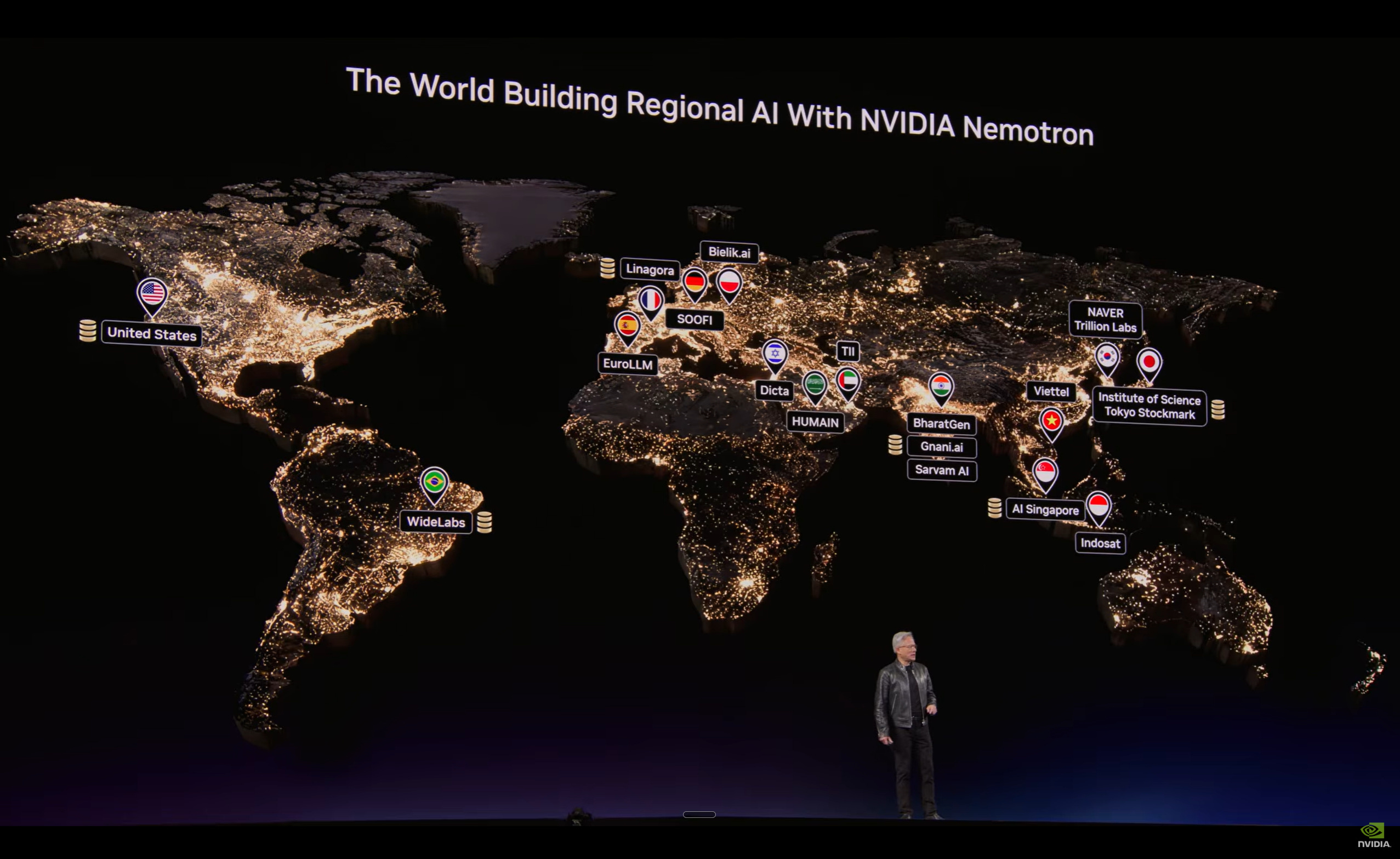
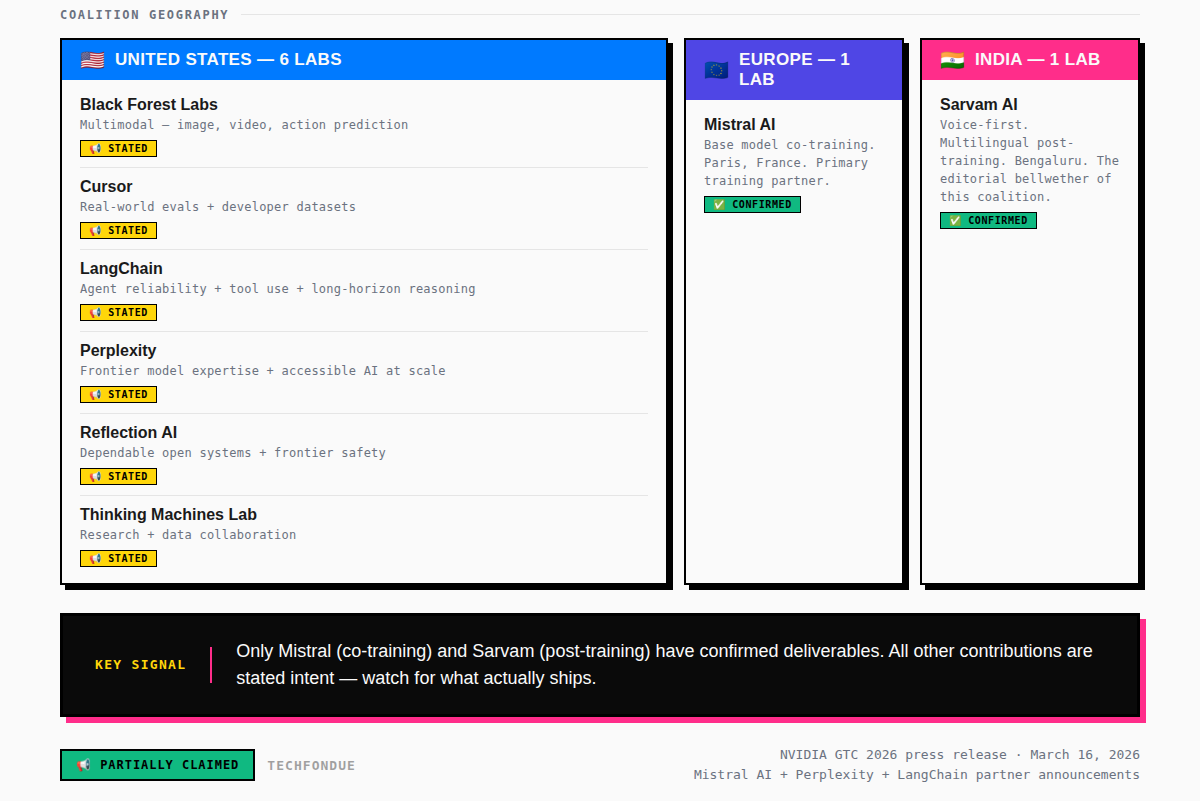
NVIDIA launched the Nemotron Coalition, a structured, multi-lab collaboration pulling together Black Forest Labs, Cursor, LangChain, Mistral AI, Perplexity, Reflection AI, Sarvam, and Mira Murati’s Thinking Machines Lab to co-build an open frontier model on DGX Cloud. The model gets open sourced. It becomes the base for the Nemotron 4 family.

On the surface, this looks like a compute play wrapped in open-source clothing. NVIDIA provides the training infrastructure, the partners contribute data, evaluations, and domain expertise, and everyone gets a shared foundation to build on top of.
But go one layer deeper and the coalition map is genuinely interesting because this isn’t just a product announcement. It’s a bet on a specific version of how the next phase of AI unfolds.
And to understand why that bet is significant, we need to understand what’s actually happening right now in the open vs closed model landscape. Because the story there is moving much faster than most coverage suggests.
The gap that wasn’t supposed to close this fast
For a long time, the narrative was clean and comfortable: closed models from OpenAI, Anthropic, and Google held the frontier. Open models like GLM, Kimi, Qwen, Gemma were useful, increasingly capable, but still clearly behind on the tasks that mattered most. You were okay paying the API bill because performance demanded it.
That story started cracking in early 2025 with DeepSeek R1. It’s been crumbling steadily (not visibly) since.
The Stanford HAI 2025 AI Index tracked the performance gap between open and closed models on the Chatbot Arena leaderboard; the human-preference benchmark, not just academic evals.
That gap went from 8% to 1.7% in a single year.
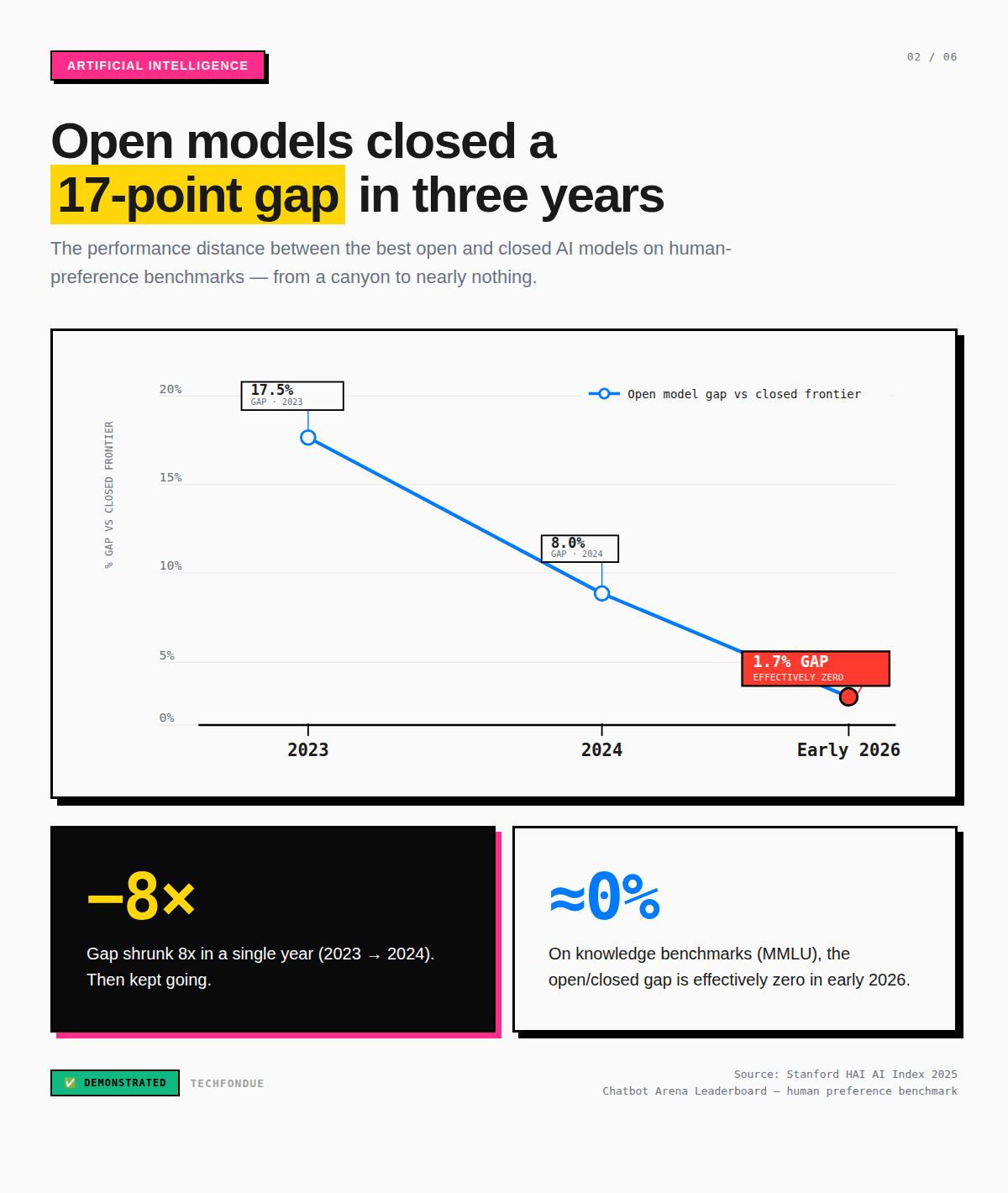
On knowledge benchmarks like MMLU, the gap has effectively closed to zero by early 2026. On most reasoning tasks, it’s mostly down to single digits.
📢 CLAIMED (by labs, with benchmark data but not independent third-party replication): Kimi K2.5, a trillion-parameter open model from Moonshot AI out of Beijing, scores 99.0 on HumanEval and 96.1 on AIME 2025. Zhipu AI’s GLM-5 currently holds the highest Elo on Chatbot Arena among open models, at 1,451, placing it at roughly 95% of closed-model performance on the same leaderboard.
✅ DEMONSTRATED: Open models now match or exceed closed models on knowledge, mathematics, and graduate-level science benchmarks. The remaining closed-model advantage is concentrated in production coding agents (SWE-bench), complex multi-step agentic tasks, and certain multimodal capabilities.
That remaining gap is real.
But it narrows with every quarterly release cycle.
And the inference cost data is where the story gets genuinely disruptive.
An MIT Sloan study tracking daily token usage on OpenRouter found that closed models still account for close to 80% of AI token usage and nearly 96% of revenue passing through the platform. But closed models cost 87% more to run, $1.86 per million tokens on average compared to $0.23 for open models.
That number is a preview of a structural problem. As open models reach performance parity on more tasks, the price premium for closed APIs shifts from a capability fee to something that starts looking more like a switching-cost tax. And for anyone running at scale, that math becomes very hard to ignore.
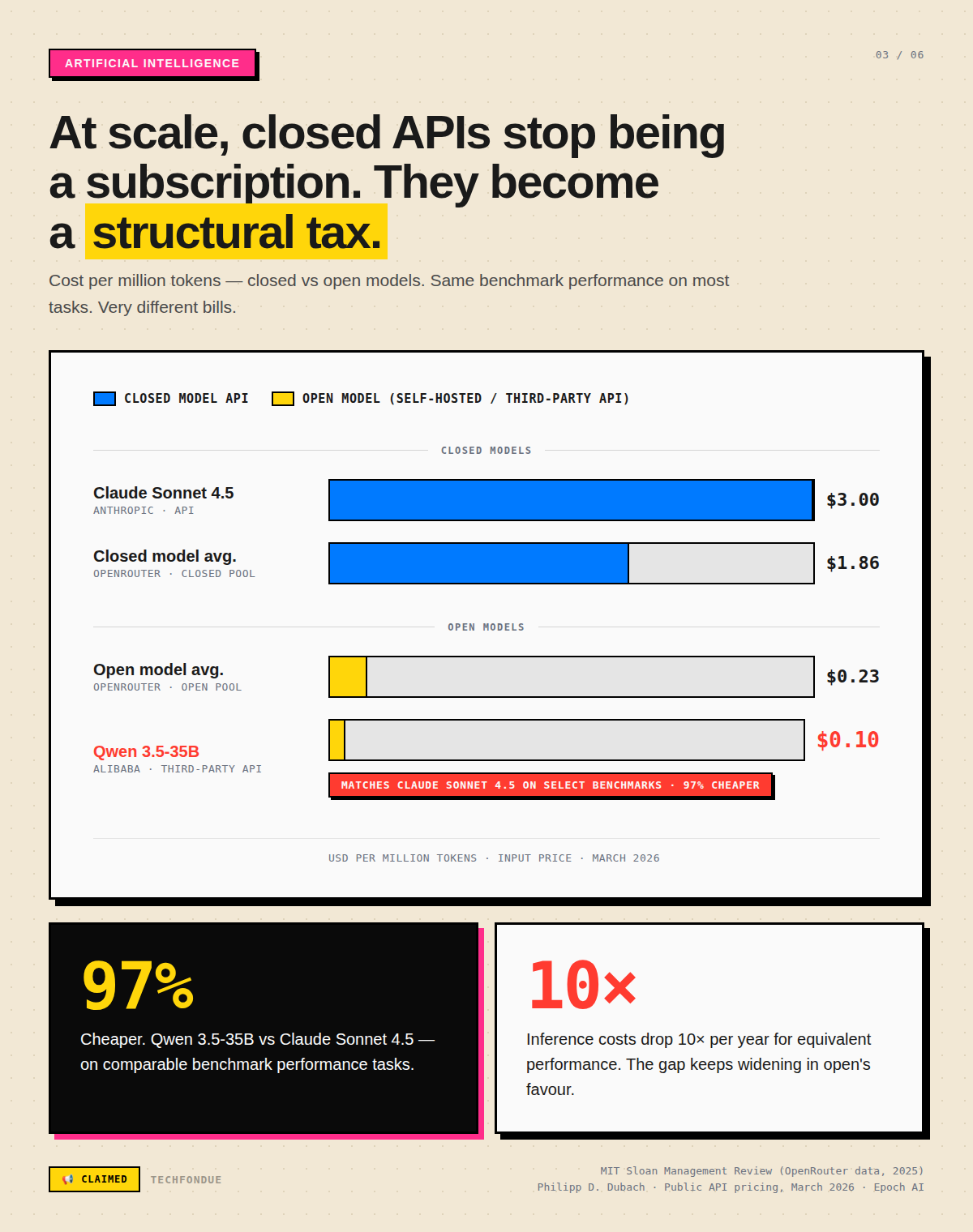
As of March 2026, Qwen 3.5-35B, from Alibaba’s Hangzhou research team, matches Claude Sonnet 4.5 on select benchmarks at $0.10 per million input tokens versus $3.00. That is a 97% cost gap for comparable output on those tasks.
LLM inference costs have dropped roughly 10x per year for equivalent performance since 2022. What cost $20 per million tokens for GPT-4-level output in late 2022 now costs approximately $0.40.
What the Nemotron Coalition is set to do?
Mistral AI, one of Europe’s most credible frontier labs, out of Paris is the primary co-training partner on the base model. This isn’t a tokenistic European inclusion. Mistral’s architecture choices, particularly their work on Mixture of Experts models that deliver large-model capability at smaller active-parameter inference cost, are directly relevant to building a frontier open model that others can actually run and specialise.
Sarvam, India’s voice-first sovereign AI lab out of Bengaluru, is contributing language-inclusive expertise to post-training. The significance of this extends well beyond model quality. India has a massive population of developers, researchers, and builders who have been priced out or rate-limited by dollar-denominated closed APIs. A truly open frontier model, voice-first, multilingual, and built with Indian-language expertise from the ground up, is not the same category of thing as a model you can fine-tune on Hindi data after the fact. That’s a different starting line entirely.
Mira Murati’s Thinking Machines Lab is contributing research and data from day one. The lab is early-stage, so the contribution here is more signal than output volume. But the signal is loud. Murati was OpenAI’s CTO through the GPT-4 era. Her presence in this coalition is a statement about where serious frontier AI talent sees the open ecosystem heading.
📢 CLAIMED: The coalition’s first output will be a Mistral-NVIDIA co-trained base model. Coalition members will contribute data, evaluations, and domain expertise to support post-training and continued development. The model will be open sourced and underpin the Nemotron 4 family.
What’s not yet demonstrated is whether the resulting model will be genuinely frontier-competitive or a well-branded collaborative experiment.
The Mistral-NVIDIA co-trained base model is the first real test.
Watch that closely.
The crevices are starting to form
Here’s the part of this story that I think is actually underreported.
The Nemotron Coalition lands at exactly the moment a structural divide is opening up in who can actually use AI and what they can do with it. Not a divide in capability in the old sense (open vs closed model quality), but a divide in access to the full stack.
On one side, there are power users. Builders, researchers, enterprises with technical teams, startups who have looked at their API bill and done the math. These are the people who can self-host, fine-tune, run inference on their own infrastructure, and customize models for their specific domain. For them, the economics of open models have already crossed the threshold. At frontier volume, a closed API subscription is not a feature, it’s a structural overhead cost that open weights eliminate.
On the other side, the majority of global users. People who need the polish, who need the memory, the safety rails, the integrations with tools they already use, the zero-setup experience of opening a browser tab and getting a world-class AI assistant. For them, ChatGPT, Claude, and Gemini are not just AI products. They are the user interface of AI itself. That experience is genuinely hard to replicate on a self-hosted stack without technical infrastructure most people do not have and should not be expected to build.
This divide is not going to close. It’s going to widen.
And not because the closed products get worse, they won’t. But because the ceiling on what you can do with open weights, local compute, and no API bill is rising faster than most coverage acknowledges.

What the open ecosystem can do for a technically capable team in 2026 could not have been done without a significant closed-API budget in 2023.
The tools have gotten there.
Ollama and LM Studio now let you run frontier-class models locally with minimal setup.
Hugging Face Spaces has collapsed the distance between research and production deployment.
Vector database infrastructure that used to require specialist DevOps is now commodity.
The barrier between wants to use open AI and has deployed open AI has dropped substantially.
But substantially lower barrier is not no barrier. There is still a hard technical floor. And the people below that floor, the majority of global users are going to stay in the closed ecosystem, not because closed models are better per benchmark point, but because the experience design is better, the onboarding is better, and the expected technical sophistication is lower.
💭 SPECULATED: The next 18 months will produce a user stratification pattern that maps roughly onto how Linux vs Windows played out at the infrastructure layer. with open models capturing the developer, researcher, and enterprise-sovereignty tier while closed models retain dominance in consumer and SMB markets. This is not inevitable, but the economic and technical forces are pointing in this direction.
But listen, the geography of this coalition is the real editorial
I want to come back to Sarvam for a moment.
I wrote about the geography of intelligence last month, about how AI sovereignty is increasingly a geopolitical variable, not just a technical one. The Nemotron Coalition’s member list is an extension of that argument in concrete form.
The coalition is not a Silicon Valley consensus. It includes a European frontier lab, an Indian sovereign AI lab, and a team (Thinking Machines Lab) that has explicitly positioned itself around making AI development less concentrated.
The coalition members don’t give up their own model roadmaps. They get a shared, compute-rich foundation that would be prohibitively expensive to build alone and in exchange, they contribute the data, domain expertise, and linguistic coverage that makes the resulting model genuinely useful outside the English internet.
For labs like Sarvam, this is a meaningfully different starting line than building from a closed API or trying to assemble frontier-scale compute from scratch. It’s access to the infrastructure tier at a moment when that tier is the most expensive part of the entire stack. NVIDIA absorbs that compute cost in exchange for ecosystem lock-in at the DGX Cloud layer, every post-training run, every fine-tune, every inference workload that builds on Nemotron 4 is a DGX Cloud workload. Open-source as a customer acquisition funnel is not new. Doing it at frontier model scale, with this coalition structure, is.
The question : How open?
The Open Source Initiative published the Open Source AI Definition (OSAID 1.0) in October 2024. By its strict criteria, which require sufficiently detailed data information, complete training code, model weights, and permission for use, study, modification, and sharing without restriction, almost none of the popular “open” models actually qualify. DeepSeek R1, Llama 4, Qwen 3.5, Mistral Large 3, they all release weights, not training data. The models that meet OSI’s standard (Pythia, OLMo, T5) are not the ones topping benchmark leaderboards.
📢 CLAIMED: The Nemotron Coalition model will be “open sourced.” What specifically this means in terms of weights, training data access, and usage restrictions has not yet been detailed in the GTC announcement. This is the right question to ask when the model ships.

The word “open” in AI has become a spectrum, not a binary. And where a model lands on that spectrum determines how much sovereignty it actually confers. A weights-only release is better than a closed API. Full data + code + weights is better still. The Nemotron Coalition’s stated mission is the former at minimum. Whether it goes further will be telling.
This is what I’m watching!
The first output from the coalition is the Mistral-NVIDIA co-trained base model. That’s the test. Not the announcement the model.
Sarvam’s contribution to post-training is the second test. If an Indian language inclusive open frontier model ships with real voice-first capability, and developers in Bengaluru and Hyderabad and beyond start building on it in ways they couldn’t afford before, that’s the coalition’s thesis proven at the only level that matters. Not in a press release but in production.
The intelligence divide that’s forming is not between humans and AI. It’s between those who can unlock the full infrastructure of open AI and those who are renting a window seat on a closed platform. That divide is widening. The Nemotron Coalition is a serious attempt to make the unlocked tier more accessible.
Whether it succeeds is the most interesting question in open AI right now.
And the game has started (AGAIN 🙄).
Sidenote: I went through the full 2+ hour GTC keynote and there are a few more things shaping up very nicely for AI’s new fiscal year. Very excited to get into those soon.
