
The Geography of Intelligence
The future of AI will likely be decided by where the data centers sit, whose data they ingest, and whether that learning stays local or leaks global.


On February 18, 2026, US Secretary of State Marco Rubio signed a diplomatic cable that most people might never read. It ordered American diplomats worldwide to actively lobby against foreign data sovereignty laws ; laws that restrict how US tech companies handle other nations’ citizen data. The cable called the EU’s General Data Protection Regulation unnecessarily burdensome. It described data localization mandates as threats to artificial intelligence services, cloud computing, and civil liberties.
Three days later, the cable leaked to Reuters. And within 48 hours, it was front-page news in Tokyo, Brussels, New Delhi, and Sydney.
The geography of AI has become a front-line geopolitical issue. Not the transformer architectures, not even the chips. The geography. The physical question of where data centers sit, whose data flows through them, and under whose laws that data is governed.
The industry fixates on which model is the smartest, which benchmark was broken, which company raised the most money. But a structural shift is underway that will reshape the entire landscape, and it has almost nothing to do with model performance.
It has everything to do with dirt, concrete, power grids, and jurisdiction.
The Gap Is Narrowing
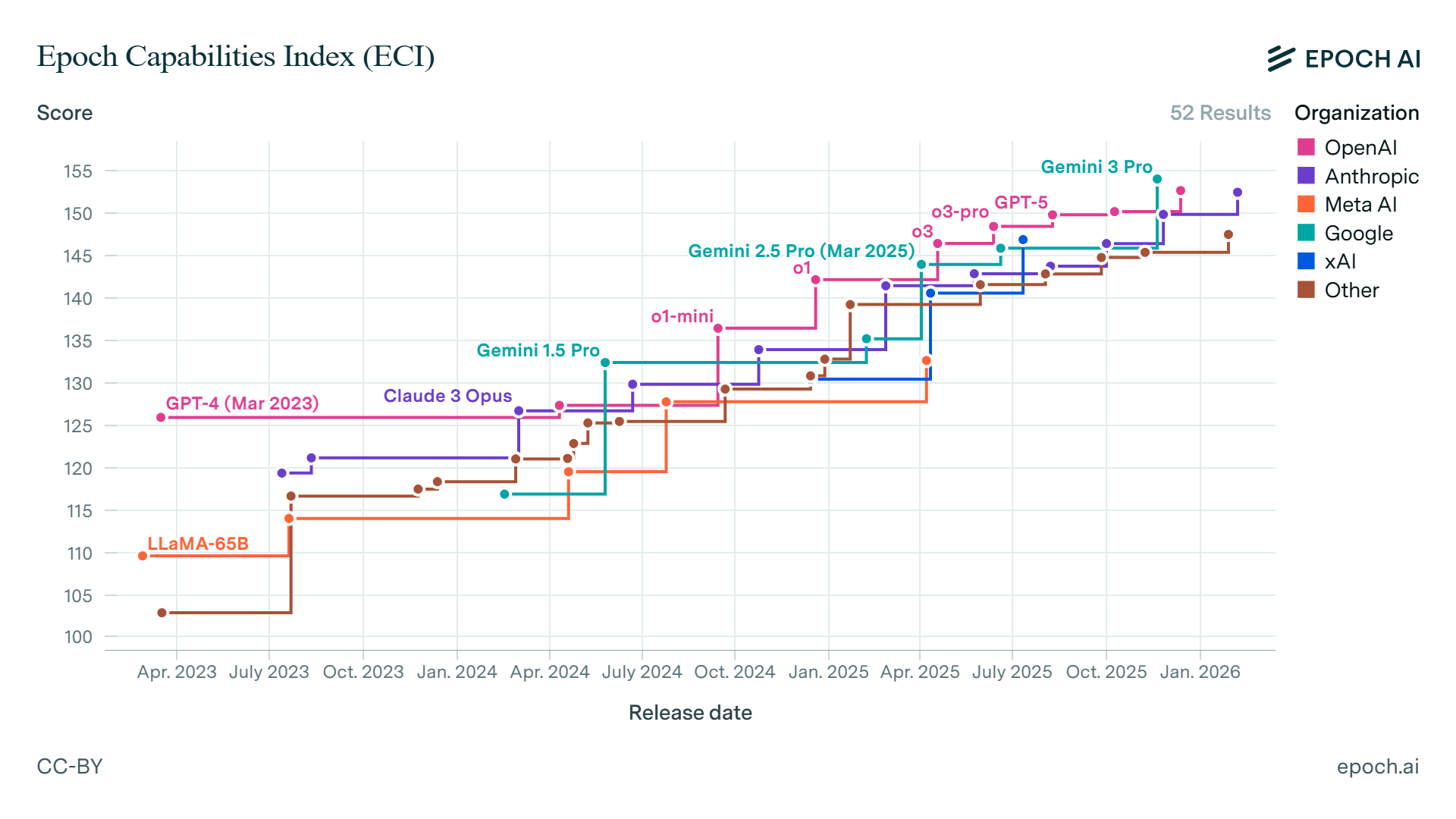
The performance gap between major models is narrowing, such so that it’ll be indistinguishable to evaluate model perf unless you’re a sucker for LMArena benchmarks.
GPT-5.2, Claude Opus/ Sonnet, Gemini 3.1 Pro, DeepSeek or a Llama for the vast majority of enterprise applications, these models produce comparable outputs. The differences matter at the margins, for specialized tasks, for cutting-edge research.
But for the business applications that generate revenue, summarization, code generation, customer service, document processing the models are converging.
When frontier models produce comparable results, the competitive axis shifts to a different benchmark. It moves from what the model can do to where and how it operates.

This is not a hypothetical, it is already happening. According to a 2025 Deloitte survey, 77% of enterprises now factor a vendor’s country of origin into AI purchasing decisions. Data privacy and security are cited as the top AI risk concern by 73% of enterprises.
The question enterprises are increasingly asking is not which model is best? Where does my data go when I use this model? Whose laws govern it? And critically what happens to my data after I send it?
That last question is the one almost nobody is answering clearly.
What Does The $3 Trillion Cheque Say?
The global data center sector is in the midst of what JLL’s 2026 Global Data Center Outlook calls an infrastructure investment supercycle. The sector is projected to double in capacity between 2025 and 2030, adding roughly 100 GW of new power capacity. Total expenditures over the next five years including real estate, construction, and IT equipment could approach $3 trillion.
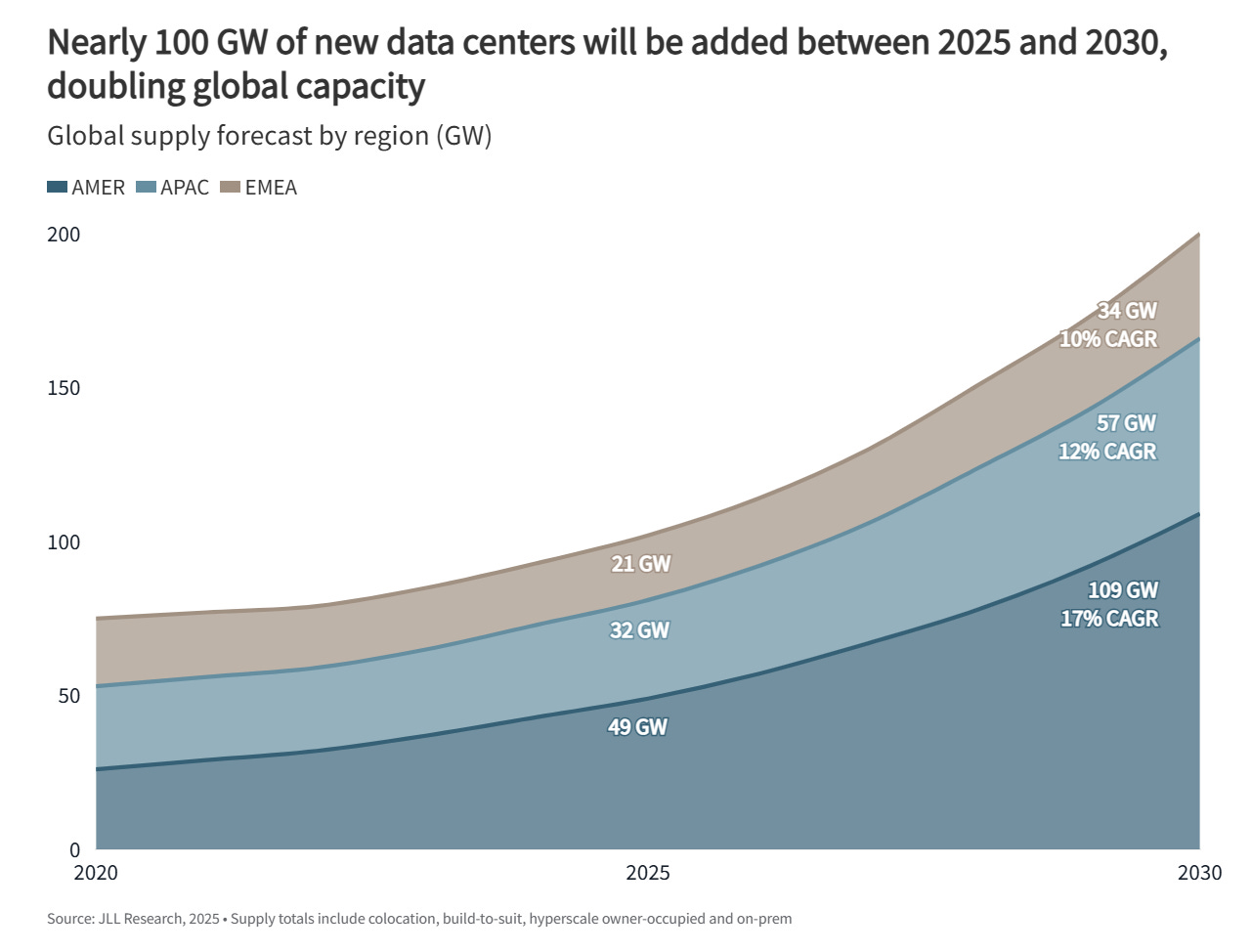
No, that is not a typo. Three trillion dollars in five years.
But here, distribution of that number is what matters more than the total. As of mid-2025, approximately 11,800 data centers operate worldwide. Two-thirds of that capacity sits in three places: the United States, China, and Europe. The United States alone accounts for the majority. India, despite being the world’s fastest-growing major economy with 850 million internet users, has a fraction of global capacity.
Africa and Latin America combined have even less.
This geographic concentration creates a fundamental asymmetry. When an Indian user interacts with an AI model hosted in Virginia, that interaction data travels across oceans, lands on American soil, and becomes subject to American law including the US CLOUD Act, which allows American authorities to compel access to data held by US-headquartered companies regardless of where the server physically sits.
This asymmetry is what the data sovereignty movement is attempting to correct. And the scale of capital now flowing toward that correction is extraordinary.
The Sovereign AI Map | Who Is Building What, and Why
Something remarkable has happened over the past 18 months. What was once a fringe policy discussion, sovereign AI, has become a global infrastructure movement backed by hundreds of billions of dollars.
Europe’s Regulation vs Infrastructure
The European Union is deploying the most comprehensive approach. The InvestAI initiative, announced at the February 2025 AI Action Summit in Paris, mobilizes €200 billion i.e., €50 billion in public funds, €150 billion from private commitments for AI infrastructure, research, and application development. This includes €20 billion for AI Gigafactory complexes, each equipped with over 100,000 processors, modeled on CERN’s collaborative research infrastructure.
Seventy-six expressions of interest have been submitted, covering 60 potential sites across 16 EU countries.
Individual member states are moving in parallel. Germany launched SOOFI (Sovereign Open Source Foundation Models) explicitly designed to create AI models sovereign, powerful, and entirely in European hands. Switzerland’s Apertus model, trained on 15 trillion tokens across more than 1,000 languages (including Swiss German and Romansh), was published on Public AI, a new access point built specifically for sovereign models. The Netherlands is developing GPT-NL, a model for the Dutch language and culture. Portugal has Amalia. Spain, Denmark, and Italy each have their own initiatives. And the OpenEuroLLM collaboration between 20 organizations, €37.4 million, targeting all 24 EU official languages by 2028 represents the broadest coordinated effort yet.
Europe’s AI sovereignty strategy is unique because it couples regulation (GDPR, the AI Act, the Digital Services Act) with independent infrastructure. The EU is not merely telling other people’s models what they cannot do, it is taking control.
China’s Proof of Concept
China offers the most fully operational example of what happens when a major power decides that AI intelligence should be geographically contained.
The Cybersecurity Law (2017), the Data Security Law (2021), and the Personal Information Protection Law (2021) collectively mandate that critical data and significant volumes of personal information remain within Chinese borders. Cross-border transfers require security assessments by the Cyberspace Administration.
For AI specifically, the State Council published regulations on network data security management in September 2024, targeting training data governance for generative AI. By August 2025, China’s AI Plus action plan called for reshaping the paradigm of human production and life through AI with data sovereignty and data center security positioned as foundational enablers, not afterthoughts.
302 generative AI services had been registered with Chinese authorities by December 2024, with mandatory content labeling and algorithmic registration required. In May 2025, Shanghai authorities imposed the first administrative penalty for unlawful cross-border data transfers, establishing enforcement precedent.
China demonstrates what the thesis predicts at scale, geographic data containment shaping AI development at the national level.
India, The Sleeping Giant
India is the most consequential case for this thesis and the most uncertain.
The Digital Personal Data Protection Act, passed in August 2023 with rules activated in November 2025, brings approximately 850 million internet users under a comprehensive privacy framework. The law authorizes the government to mandate sensitive data storage within India but those provisions have not yet been activated. They sit dormant, a latent capability that could be switched on at any time.
What is already active is sector-specific localization. The Reserve Bank of India mandates that payment system data be stored exclusively within India. SEBI requires critical financial governance data to remain onshore. IRDAI imposes similar requirements for insurance data.
Meanwhile, the IndiaAI Mission is investing $1.25 billion in domestic AI capability, including 18,000+ GPUs through public-private partnerships. Reliance Industries is building a foundation LLM trained on India’s diverse languages. Tata Group is constructing large-scale AI infrastructure powered by NVIDIA Grace Hopper 200 superchips. Sarvam AI, the Bengaluru-based startup, launched India’s first homegrown multilingual LLM in 2026.
India’s compliance deadline of May 2027 is when this story accelerates. If the government activates the data localization provisions of the DPDP Act which it is legally empowered to do, it would create one of the world’s largest geographic data containment frameworks overnight.
Southeast Asia’s Smaller Nations Have Big Signals
The movement extends well beyond the major powers.
Singapore launched SEA-LION (Southeast Asian Languages in One Network) in December 2023, pre-training existing models on data from 13 regional languages. Malaysia built ILMU, its own foundation LLM, launched in August 2025. Vietnam passed an AI Law in December 2025 emphasizing sovereignty over AI data, infrastructure, and models.
Perhaps most telling, in late December 2025, Indonesia, Malaysia, and the Philippines collectively banned xAI’s Grok after it allowed generation of non-consensual sexualized images. The ban was only lifted after xAI implemented new restrictions. This was coordinated enforcement action against a US frontier AI company, by nations asserting that foreign models operating on their citizens’ data must meet their standards.
The Full Count
Over 70 countries and territories have published official national AI strategies. Canada committed $2 billion to a Sovereign AI Compute Strategy. The UK established a Sovereign AI Unit with £500 million in funding. The UAE has a National AI Strategy targeting leadership across eight sectors by 2031.
NVIDIA’s AI Nations initiative, active since 2019, has partnered with countries on every continent to build sovereign AI capabilities. Jensen Huang has been pitching sovereign AI since at least 2023; conscious, as Cambridge Core’s analysis notes, that nation states are the next deep pockets to target after the hyperscalers.
This is no longer a fringe movement. It is the defining infrastructure trend in global AI.
But Why Is Nobody Answering The Question?
Every major AI provider fine-tunes its models on user interaction data. This is standard practice. When you chat with an AI model, your interaction contributes in aggregate, often anonymized to the data that shapes future model behavior.
This is how models improve.
But consider the implications through a geographic lens.
When a user in Mumbai interacts with a model hosted in Virginia, that interaction data enters a pipeline that in most cases is not geographically segmented. The model learns from users globally. Fine-tuning from Indian users may improve the model’s understanding of Hindi idioms. Fine-tuning from German users may sharpen its grasp of engineering terminology. Fine-tuning from Chinese users in models that serve Chinese markets shapes its cultural assumptions.
This raises a question that no major frontier AI company has publicly addressed with specificity. Does geographic fine-tuning propagate across the model family globally, or does it remain contained within its geographic context?
The question matters enormously. If fine-tuning from Indian user data improves a model’s performance globally, that is an argument for open data flows, every user benefits from every other user’s contribution. But it also means that Indian cultural context, behavioral patterns, and implicit preferences are being used to shape a model that serves European or American users without their knowledge, without regulatory oversight, and without any framework for consent.
If, on the other hand, geographic fine-tuning is contained, if Indian user data only improves the Indian deployment, then the geographic segmentation that sovereigntists demand is already technically achievable. But it would mean fragmenting model intelligence along national lines, potentially degrading performance for everyone.
Neither answer is clean. Both have profound implications. And the silence from AI providers on this question is itself the most important data point.
What Does The Research Show?
The evidence we do have is damning in its own way.
Research published in PNAS Nexus by Cornell’s Kizilcec lab tested five versions of ChatGPT against nationally representative survey data from the Integrated Values Survey, covering 107 countries and territories. All models showed significant bias toward Western self-expression values; tolerance of diversity, gender equality, environmental concern regardless of which cultural context the user represented.
It is not a bug, it is a reflection of training data that is overwhelmingly English-language and Western-origin.
The Ada Lovelace Institute describes this as potential digital cultural hegemony. A world where 400 million users interact with a system whose embedded values align with a narrow set of nations, regardless of the user’s own cultural context.
Research published in Nature in November 2025 found that models fine-tuned using local data outperformed the largest global models for Southeast Asian languages. Bulgaria’s sovereign model outperformed ChatGPT and LLaMA in local school exams. These results demonstrate that geographic data specificity materially improves performance and that global models carry a measurable cost in cultural and linguistic accuracy.
And We Have Seen This Movie Before
If this analysis feels familiar, it should. The internet itself walked this exact path from borderless utopia to jurisdictional reality, over approximately 25 years.
Act I: Borderless Optimism (1990s–2010s)
The early internet operated on an assumption of frictionless global data flow. Jurisdiction was considered irrelevant, even quaint. Data moved freely across borders, hosted wherever infrastructure was cheapest or most convenient. This era produced the hyperscale cloud model that now dominates computing.
Act II: The Sovereignty Awakening (2015–2020)
The Schrems I decision in 2015 invalidated the EU-US Safe Harbor Framework, ruling that US surveillance laws meant European citizen data was not adequately protected on American soil. Schrems II in July 2020 went further, striking down the Privacy Shield and establishing that the mere existence of US surveillance capabilities made US-hosted data legally problematic for EU citizens.
The logic was devastating in its simplicity. If US law permits access to the data, no contractual mechanism; not Standard Contractual Clauses, not corporate promises, not encryption can make the data essentially equivalent in protection to what EU law requires.
This catalyzed what the Information Technology and Innovation Foundation described as a slide toward de facto data localization. France’s data protection authority recommended that French health data services avoid American cloud providers entirely even when those providers operated servers on European soil.
Act III: Geographic Containment (2020–present)
GDPR’s enforcement actions totaling billions in fines demonstrated that data sovereignty laws have real economic consequences. The EU-US Data Privacy Framework was established in 2023 as a successor mechanism, but legal challenges (a potential “Schrems III”) are already anticipated.
Meanwhile, 137 countries enacted data protection laws. China built the world’s most comprehensive data containment regime. India’s DPDP Act activated. Southeast Asian nations began banning non-compliant foreign AI services.
AI’s Timeline Compression
The internet took 25 years to travel from borderless to bordered. AI will travel the same path in less than 10. There are three reasons.
First, the regulatory infrastructure already exists. GDPR, the EU AI Act, China’s PIPL, India’s DPDP Act, these frameworks were built for data generally but apply to AI data specifically. AI does not need to wait for new law to be written. The law is already written. It is being extended.
Second, the stakes are higher. Internet data is passive. Stored, retrieved, occasionally analyzed. AI data is active, it shapes model behavior, influences decision-making, generates outputs that users act upon. The governance urgency is correspondingly greater.
Third, the geopolitical contest is explicit. When the US Secretary of State personally signs a cable ordering diplomats to fight data sovereignty laws and specifically names AI as the reason, the political salience is beyond what internet governance ever achieved.
And If We’re To Follow the Money!!
Global data center investment is projected to cross $418 billion in 2026, growing to $692 billion by 2030, a 10.6% CAGR. Total infrastructure spending, including IT equipment, may approach $3 trillion over five years.
Sovereign AI infrastructure investment announced globally exceeds $300 billion. The EU’s InvestAI alone accounts for €200 billion. India’s IndiaAI Mission adds $1.25 billion. Canada’s Sovereign AI Compute Strategy: $2 billion. The UK’s Sovereign AI Unit: £500 million. These numbers are additive, they represent new capital specifically targeting geographic AI containment.
The hyperscaler response has been hyper. AWS launched its European Sovereign Cloud in January 2026, a German-incorporated entity, physically and logically separate from other AWS regions, with EU-resident leadership and 90 initial services. Microsoft Azure operates sovereign deployments in France (Bleu) and Germany (Delos Cloud). Google’s Distributed Cloud enables organizations to run Google services on their own premises.
AWS is not lobbying against European data sovereignty, it is selling European data sovereignty as a premium product. This is perhaps the strongest market signal of all.
Federated learning, the technical architecture for training models on distributed data without centralizing it, reached $0.1 billion in market size in 2025, projected to grow to $1.6 billion by 2035 at 27.3% CAGR. This market exists because geographic data containment is already a binding constraint. Its growth rate reflects the expectation that this constraint will tighten.
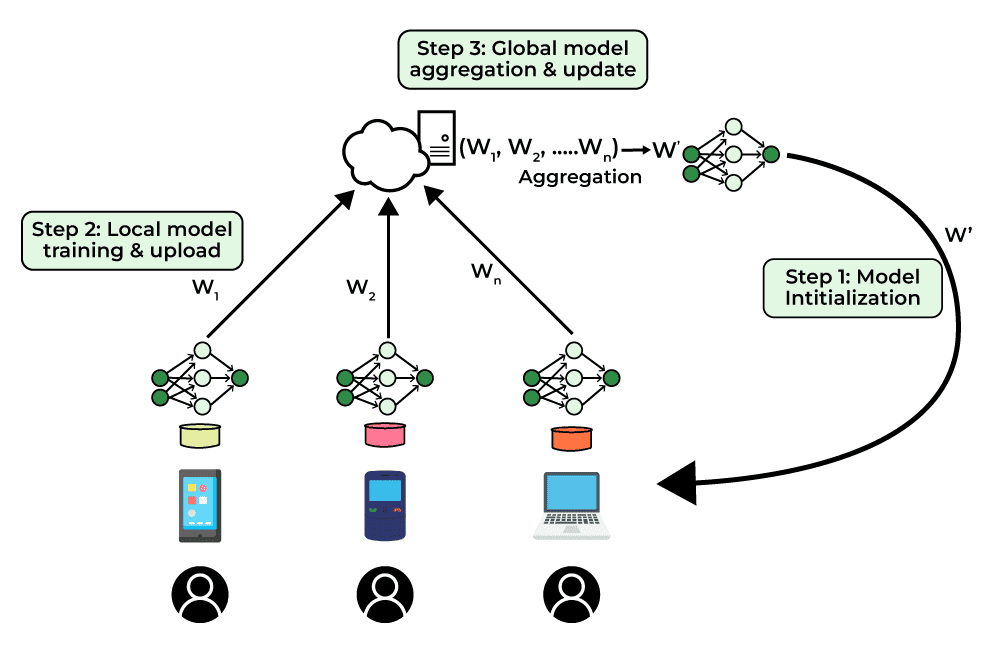
But only 5.2% of federated learning research has reached real-world deployment. The architecture is promising. It is not yet operational at scale. This gap between the technical possibility of geographic AI containment and its practical implementation is where the next wave of innovation (and investment) will concentrate.
What Are The Counterarguments?
No thesis this sweeping escapes without strong counterarguments.
The economics of full sovereignty are impossible for most countries
This is true, and it matters. Training a frontier model costs hundreds of millions of dollars. Google’s Gemini Ultra reportedly required $191 million in compute alone. The EU’s entire EuroHPC sovereign AI budget represents roughly 2% of what four American companies spent in six months. For lower-income countries, full AI sovereignty is economically unrealistic.
But the thesis does not require every country to build a frontier model from scratch. The more realistic path, and the one most countries are actually pursuing is fine-tuning open-source foundation models (like Meta’s Llama, Alibaba’s Qwen, or Singapore’s SEA-LION) on local data. This requires orders of magnitude less compute than training from scratch. It is the fine-tuning layer, not the foundation layer, where geographic specificity creates value and where data sovereignty frameworks will bite.
Fragmentation will degrade model quality
Localizing data can trap training inputs within borders, limiting diversity and potentially worsening performance. Models trained on region-specific data may underperform in cross-cultural contexts.
This is a real tension. But it is also precisely the tension that federated learning architectures are designed to resolve, enabling collaborative model improvement while keeping raw data geographically contained. The fact that federated learning has not yet scaled does not mean the technical path is blocked. It means it is early.
US hyperscalers will adapt and maintain dominance
AWS European Sovereign Cloud, Microsoft Azure sovereign deployments, Google Distributed Cloud, these products demonstrate that American firms can comply with sovereignty requirements without ceding market position. Data center geography becomes a compliance cost, not a competitive differentiator.
This counterargument has real force. But it also concedes the underlying thesis. Even if US hyperscalers maintain market share, the architecture of AI shifts toward geographic segmentation. The models, the data pipelines, the fine-tuning processes all become geographically structured. The hyperscalers survive, but the borderless AI era ends.
The US CLOUD Act undermines the entire framework
Even when US providers build data centers in Europe or India, the CLOUD Act allows US authorities to compel access to that data. Regional deployment from a US provider does not equal sovereignty. This unresolved legal tension, physical location versus corporate jurisdiction is the deepest structural flaw in the current sovereignty framework.
This is the most technically valid counterargument. It is also, paradoxically, the strongest argument for the thesis. The CLOUD Act tension is precisely what drives nations toward building non-US infrastructure. Europe’s sovereign cloud investments are not just about GDPR compliance, they are about escaping US jurisdictional reach entirely.
What Hatches from This Egg
AI’s technical capabilities are not embryonic. They are advancing at frontier pace. The transformer architecture, scaling laws, multimodal reasoning, agentic systems, these are mature and accelerating.
What is embryonic is AI’s governance architecture. The regulatory frameworks, transparency standards, geographic containment mechanisms, and international coordination protocols that will determine how AI is actually deployed at civilizational scale, these are genuinely in their earliest developmental stages.
The egg is not AI itself. The egg is the global system of rules that will determine what AI becomes.
There is one more dimension to this analysis that deserves attention because it is the least discussed and potentially the most consequential.
Every conversation about data sovereignty focuses on protection. Protecting citizen data from foreign surveillance, protecting national security, protecting cultural values. These are legitimate concerns.
But there is a flip side. Geographic data containment also means geographic data capture. A data center in Mumbai does not just protect Indian data from American surveillance. It also captures Indian behavioral patterns, cultural preferences, linguistic nuances, and decision-making heuristics and makes them available to whoever controls that data center.
In a world where AI models are fine-tuned on geographic user data, the entity that controls the data center in a given geography controls the intelligence pipeline for that population. The sovereign AI movement is framed as protection. It is also, inevitably, an instrument of capture.
This is not necessarily sinister. Local data capture can power better healthcare AI, more culturally appropriate education tools, more effective public services. But it is worth naming clearly that data sovereignty is not just a shield. It is also a lens focusing the intelligence of an entire population into an asset that someone controls.
Who that someone is, a democratic government, an authoritarian state, a private corporation, or a public-interest consortium will determine whether geographic AI segmentation produces a more equitable world or a more surveilled one.
That is the open question at the heart of this story. And it is the question that will determine, more than any benchmark or model release, what AI actually becomes.
This is a TechFondue convergence story of AI × Cybersecurity × Geopolitics × DeepTech Infrastructure.